最近刚上手storm,在进行日志业务分析的时候,使用如下的处理流:
从kafka读取数据,然后进行处理,再将处理结果写回kafka这样一个流程。在测试过程中,出现了整个流卡住的问题,解决的过程比较曲折,这里记录一下问题的原因分析。
问题介绍
先来看看简要代码介绍:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public static void main(String[] args) throws Exception {
String[] correctArgs = parseArgs(args);
BaseRichBolt splitBolt;
BaseRichBolt normalizeBolt;
if (args[4].equals("wangsu")) {
splitBolt = new CdnWangsuSplitBolt();
normalizeBolt =new CdnWangsuNormalizeBolt();
} else {
splitBolt = new CdnAwsSplitBolt();
normalizeBolt = new CdnAwsNormalizeBolt();
}
KafkaSpout spout = getKafkaSpout(correctArgs);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(CDN_KAFKA_SPOUT_ID, spout, 16);
builder.setBolt(CDN_SPLIT_LOG_BOLT_ID, splitBolt, 16).shuffleGrouping(CDN_KAFKA_SPOUT_ID);
builder.setBolt(CDN_NORMALIZE_LOG_BOLT_ID, normalizeBolt, 64).shuffleGrouping(CDN_SPLIT_LOG_BOLT_ID);
builder.setBolt(CDN_AGGREATOR_LOG_BOLT_ID, new CdnLogAggreator(), 128).fieldsGrouping(CDN_NORMALIZE_LOG_BOLT_ID, new Fields("key"));
builder.setBolt(CDN_OUTPUR_LOG_BOLT_ID, new KafkaOutputBolt().getKafkaBolt(args[1], args[3]), 16).shuffleGrouping(CDN_AGGREATOR_LOG_BOLT_ID);
LOG.info("brokers: " + args[1] + " output: " + args[3]);
StormSubmitter.submitTopology(correctArgs[5], getTopologyConfig(correctArgs), builder.createTopology());
}
其中 splitBolt 的代码为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45public class CdnWangsuSplitBolt extends BaseRichBolt {
private static Logger LOG = new MyLogger().getLogger(CdnWangsuSplitBolt.class.getName());
private static String SITENAME = "wangsu";
private LogParser logParser;
private OutputCollector collector;
public void prepare(Map config, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.logParser = new LogParser(SITENAME);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("clientip", "time", "method", "host", "path", "protocol",
"protocol-version", "code", "size", "dltime"));
}
public void execute(Tuple tuple) {
String logstr = tuple.getString(0);
Map<String, String> logEntry = this.logParser.initLogMapEntry(logstr);
if (logEntry == null) {
LOG.warning("Invalid log: " + logstr);
return null;
}
String clientip = logEntry.get("clientip");
String time = logEntry.get("time");
String method = logEntry.get("method");
String host = logEntry.get("channel");
String path = logEntry.get("url");
String protocol_version = logEntry.get("protocol-version");
String protocol = logEntry.get("protocol");
String code = logEntry.get("code");
String size = logEntry.get("size");
String dltime = logEntry.get("dltime");
if (code.equals("0")) {
LOG.warning("Invalid log: " + logstr);
return null;
}
this.collector.emit(tuple, new Values(clientip, time, method, host, path, protocol,
protocol_version, code, size, dltime));
collector.ack(tuple);
}
}
出现的问题是,集群每次跑到一定的程度就卡在那里了,例如上面的配置,跑到1千多万条数据的时候,就开始卡在那里了,从监控的流量图来看如下:
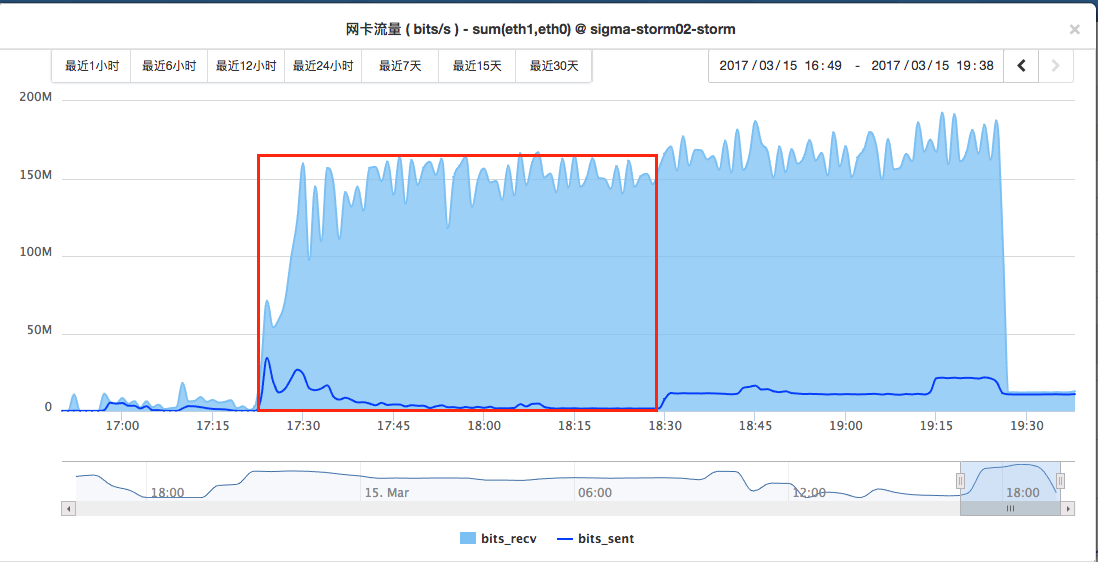
可以看到,kafka的数据消费速度基本没变,说明kafka-spout是基本处于正常状态的,但是数据的产生到后面确实越来越低主键变为0。
解决方案
首先说一下解决方案:
- 将BaseRichBolt换成BaseBasicBolt
- 在目前的实现里面,executor严格进行
ack,例如改为如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public class CdnWangsuSplitBolt extends BaseRichBolt {
...
public void execute(Tuple tuple) {
...
try {
if (logEntry == null) {
throw new Exception("Invalid log: " + logstr);
}
String clientip = logEntry.get("clientip");
String time = logEntry.get("time");
String method = logEntry.get("method");
String host = logEntry.get("channel");
String path = logEntry.get("url");
String protocol_version = logEntry.get("protocol-version");
String protocol = logEntry.get("protocol");
String code = logEntry.get("code");
String size = logEntry.get("size");
String dltime = logEntry.get("dltime");
if (code.equals("0")) {
throw new Exception("Invalid log: " + logstr);
}
this.collector.emit(new Values(clientip, time, method, host, path, protocol,
protocol_version, code, size, dltime));
} catch (Exception e) {
LOG.warning(e.getMessage());
} finally {
collector.ack(tuple);
}
}
我们先不管代码的写法是不是最佳实践(因为一直写python,最近才开始写java,还不是很熟悉),我想强调的是,不管每个tuple你是怎么处理的,在这里对于无效日志不能直接跳过,一定要进行ack。
原因分析
那么来看一下这里为什么不进行ack就会出现stream卡住的问题,首先可以看到我这里使用的是默认storm配置,也就是30s没有进行ack就会被认为消息处理失败,从而会调用kafka-spout的fail方法进行处理,那么我们来看看kafka-spout的fail是怎么写的:1
2
3
4
5
6
7public void fail(Object msgId) {
KafkaMessageId id = (KafkaMessageId) msgId;
PartitionManager m = _coordinator.getManager(id.partition);
if (m != null) {
m.fail(id.offset);
}
}
可以看到,使用了PartitionManager来进行管理,那么我们直接看看PartitionManager的fail实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public void fail(Long offset) {
if (offset < _emittedToOffset - _spoutConfig.maxOffsetBehind) {
LOG.info(...);
} else {
LOG.debug("Failing at offset={} with _pending.size()={} pending and _emittedToOffset={} for {}", offset, _pending.size(), _emittedToOffset, _partition);
numberFailed++;
if (numberAcked == 0 && numberFailed > _spoutConfig.maxOffsetBehind) {
throw new RuntimeException("Too many tuple failures");
}
// Offset may not be considered for retry by failedMsgRetryManager
if (this._failedMsgRetryManager.retryFurther(offset)) {
this._failedMsgRetryManager.failed(offset);
} else {
// state for the offset should be cleaned up
LOG.warn("Will not retry failed kafka offset {} further", offset);
_messageIneligibleForRetryCount.incr();
_pending.remove(offset);
this._failedMsgRetryManager.acked(offset);
}
}
}
注意:
这里的 _spoutConfig.maxOffsetBehind使用的是默认配置,值为 Long.MAX_VALUE,在64位机器上是9223372036854775807
我们这里先不进行摄入研究,但是从最上层的is-else可以看出,在失败消息条数未达到设置的上限(Long.MAX_VALUE)时,如果消息发送失败,就会重试。到这里,我们可以看到一个问题,那就是如果maxOffsetBehind设置得比较大,那么会出现failed的消息永远不会被忽略,而会一直重试直到成功。这个基本解释了为什么前面的代码里面一定要加上ack,如果不加上,会导致failed的消息一直占用内存,同时占用计算资源。(关于fail更深入的分析在后面进行)
但是这不能解释另一个问题,如果只是上面这部分代码,虽然有failed的信息会占用资源,但是从kafka-spout的执行情况来看(没有截图),failed的消息也就不到10w条,还不至于阻塞住整个stream,并且从jvm的GC和监控里面机器内存消耗来看,其实内存上是没有什么影响的。
那么我们换个角度,从kafka-spout的nextTuple的实现来看,它是调PartitionManager的next来进emit消息的:1
EmitState state = managers.get(_currPartitionIndex).next(_collector);
那么我们来看看PartitionManager的next方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public EmitState next(SpoutOutputCollector collector) {
if (_waitingToEmit.isEmpty()) {
fill();
}
while (true) {
MessageAndOffset toEmit = _waitingToEmit.pollFirst();
...
Iterable<List<Object>> tups;
if (_spoutConfig.scheme instanceof MessageMetadataSchemeAsMultiScheme) {
tups = KafkaUtils.generateTuples((MessageMetadataSchemeAsMultiScheme) _spoutConfig.scheme, toEmit.message(), _partition, toEmit.offset());
} else {
tups = KafkaUtils.generateTuples(_spoutConfig, toEmit.message(), _partition.topic);
}
if ((tups != null) && tups.iterator().hasNext()) {
if (!Strings.isNullOrEmpty(_spoutConfig.outputStreamId)) {
for (List<Object> tup : tups) {
collector.emit(_spoutConfig.topic, tup, new KafkaMessageId(_partition, toEmit.offset()));
}
} else {
for (List<Object> tup : tups) {
collector.emit(tup, new KafkaMessageId(_partition, toEmit.offset()));
}
}
break;
} else {
ack(toEmit.offset());
}
}
...
}
去掉了一些非重点的部分,我们看这个方法的实现可以看出,在while里面会不断从_waitingToEmit获取消息,然后通过KafkaUtils构造新的tuple进行发射(_waitingToEmit 表示所有己经被从kafka读取,但是还没有发射到topology流中的消息)。当next被调用的时候,它只会从_waitingToEmit获取消息,如果_waitingToEmit为空,就会调用fill方法。那么我们来看看fill方法到底干了啥。
fill方法主要逻辑分为以下三部分:
- 判断应该从哪个offset开始获取消息
- 获取消息,处理TopicOffsetOutOfRangeException异常
- 把获取的消息放到_waitingToEmit中,同时结合failed集合和pendding集合进行处理
我们分别来介绍着三部分:第一部分在:找到offset
1
2
3
4
5
6// Are there failed tuples? If so, fetch those first.
offset = this._failedMsgRetryManager.nextFailedMessageToRetry();
final boolean processingNewTuples = (offset == null);
if (processingNewTuples) {
offset = _emittedToOffset;
}
这段代码里,offset即是将要从Kafka里抓取消息的offset。当failed集合不为空时,就用failed集合的最小的offset做为下次要抓取的offset(默认的failed处理类ExponentialBackoffMsgRetryManager的处理方案)。Kafka的FetchRequest每次会从Kafka中获取一批消息。所以,如果有消息fail,而此failed消息之后的消息已被ack,那么fill方法会重新获取这些已被ack的消息,如果不对这些消息进行过滤,就会造成重复消费问题,我们后面会看到,fill方法是会进行处理的。
如果没有failed消息,fill方法就会从之前读取过的最大的offset开始继续读取。
第二部分:获取消息
知道了从哪里开始获取消息后,接下来就开始获取:1
2
3
4
5
6
7
8
9
10try {
msgs = KafkaUtils.fetchMessages(_spoutConfig, _consumer, _partition, offset);
} catch (TopicOffsetOutOfRangeException e) {
offset = KafkaUtils.getOffset(_consumer, _partition.topic, _partition.partition, kafka.api.OffsetRequest.EarliestTime());
// fetch failed, so don't update the fetch metrics
//fix bug [STORM-643] : remove outdated failed offsets
... 这里是处理另一个bug的,先忽略
return;
}
这部分的分析涉及到offset的异常处理(要读取的offset不在kafka能提供的offset范围内),不是我们这里要讨论的问题,所以先跳过。暂时只将他们简化为消息获取部分。
第三部分:消息处理
获取到消息后,需要处理各种例外情况:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19for (MessageAndOffset msg : msgs) {
final Long cur_offset = msg.offset();
if (cur_offset < offset) {
// Skip any old offsets.
continue;
}
if (processingNewTuples || this._failedMsgRetryManager.shouldReEmitMsg(cur_offset)) {
numMessages += 1;
if (!_pending.containsKey(cur_offset)) {
_pending.put(cur_offset, System.currentTimeMillis());
}
_waitingToEmit.add(msg);
_emittedToOffset = Math.max(msg.nextOffset(), _emittedToOffset);
if (_failedMsgRetryManager.shouldReEmitMsg(cur_offset)) {
this._failedMsgRetryManager.retryStarted(cur_offset);
}
}
}
_fetchAPIMessageCount.incrBy(numMessages);
- 首先,需要考虑到FetchRequest指定的是返回集合中最小的offset A,但是实际上kafka只保证返回的消息集中包括了offset为A的消息,这个消息集中可能包括了比A更小的消息(由于压缩),所以fill方法首先要skip掉这些offset更小的消息
- 如果fiiled为空(processingNewTuples),fill就会把所有offset从A开始的消息加入_waitingToEmit集合
如果failed不为空,那么遍历msgs,如果msg在failed集合里,首先把这条消息加入_waitingToEmit集合与_pending集合,同时把它从failed集合中去掉(否则这条消息就会永远在failed集合里)。注意,只有在fill方法中,failed集合中的元素才可能被移除,加入到_waitingToEmit集合,使它有机会被重新emit。其中的
shouldReEmitMsg方法是在ExponentialBackoffMsgRetryManager中实现的,我们简单看一下它的实现:1
2
3
4
5
6public boolean shouldReEmitMsg(Long offset) {
MessageRetryRecord record = this.records.get(offset);
return record != null &&
this.waiting.contains(record) &&
System.currentTimeMillis() >= record.retryTimeUTC;
}这个方法主要用来判断对应offset的消息是否在failed集合里面,如果不在,说明消息已经被成功消费过了,因此直接跳过这条消息。
从上面的结果可以看出,如果failed的消息会一直失败,这个task就会一直卡在处理失败消息这部地方。在我们的场景里面,会有一些日志不符合要求,尤其是上面的第二个过滤条件:1
2
3
4if (code.equals("0")) {
...
return null;
}
这个时候我们是直接return的,这就导致这些tuple没有ack,而这种写法里面,对于无效日志是直接返回,永远不会被ack的,也就会不断重试。也就是,task会不断从第一个失败的offset开始从kafka获取相同的一批数据,然后处理这批数据里面的无效日志。这也就解释了我前面给出的监控图里面,网卡流量中读的流量一直居高不下,但是写的流量逐渐减少到最后完全不写了。这是因为各个task都逐渐被卡住了。
到这里,或许会有一个疑问,前面说到,根据shouldReEmitMsg方法返回值来判断一个消息是否是failed的,如果是,那么才会处理,那么如果这一批msgs中有消息是没有处理过的呢(例如在失败消息第一次处理的之后才插入kafka,还没有被消费的),那不是被跳过了?其实不会的,我们看以下代码(前面第三部分消息处理部分里的):1
2
3
4
5if (processingNewTuples || this._failedMsgRetryManager.shouldReEmitMsg(cur_offset)) {
...
_emittedToOffset = Math.max(msg.nextOffset(), _emittedToOffset);
...
}
可以看到,在处理failed的消息的时候,会将_emittedToOffset设置为当前已处理的消息里面最新的offset的,那么在下一次获取消息时,如果已经没有failed了的消息了,那么就会从_emittedToOffset开始获取消息,因此可以保证不重复消费消息,也不漏掉消息。
其他分析
前面我们基本通过源码搞清楚了kafka-spout的失败消息处理原则,也搞清楚了我们出现stream卡住的问题的原因。下面进一步分析一下PartitionManager的ack和fail方法。
我们先来看ack方法:1
2
3
4
5
6
7
8
9public void ack(Long offset) {
if (!_pending.isEmpty() && _pending.firstKey() < offset - _spoutConfig.maxOffsetBehind) {
// Too many things pending!
_pending.headMap(offset - _spoutConfig.maxOffsetBehind).clear();
}
_pending.remove(offset);
this._failedMsgRetryManager.acked(offset);
numberAcked++;
}
ack的主要功能是把成功了的消息从_pending去掉,表示这个消息处理完成,PartitionManager根据这个获取正确的处理进度信息,以更新zk里面的offset记录。同时删除可能存在以failed集合中的对应记录。但是,他还有另一个作用,也就是这句:1
2
3
4if (!_pending.isEmpty() && _pending.firstKey() < offset - _spoutConfig.maxOffsetBehind) {
// Too many things pending!
_pending.headMap(offset - _spoutConfig.maxOffsetBehind).clear();
}
当一个offset被ack时,ack方法会把所有小于offset - _spoutConfig.maxOffsetBehind的消息从_pending中移除。也就是说,即使这些被移除的消息失败了,也认为他们处理成功,使得在Zookeeper中记录的进度忽略这些被移除的消息。所以,假如task重启,那么这些失败但被移除出_pending集合的消息就不会被再处理。所以在设置maxOffsetBehind的时候需要考虑好这个问题。
那么,这些失败了的消息,当storm的acker发现它们处理失败了,会发生什么呢?这个由fail方法决定。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public void fail(Long offset) {
if (offset < _emittedToOffset - _spoutConfig.maxOffsetBehind) {
LOG.info(...);
} else {
LOG.debug("Failing at offset={} with _pending.size()={} pending and _emittedToOffset={} for {}", offset, _pending.size(), _emittedToOffset, _partition);
numberFailed++;
if (numberAcked == 0 && numberFailed > _spoutConfig.maxOffsetBehind) {
throw new RuntimeException("Too many tuple failures");
}
// Offset may not be considered for retry by failedMsgRetryManager
if (this._failedMsgRetryManager.retryFurther(offset)) {
this._failedMsgRetryManager.failed(offset);
} else {
// state for the offset should be cleaned up
LOG.warn("Will not retry failed kafka offset {} further", offset);
_messageIneligibleForRetryCount.incr();
_pending.remove(offset);
this._failedMsgRetryManager.acked(offset);
}
}
}
当一个消息对应的tuple被fail时,fail方法首先会判断这个消息是否落后太多。如果它的offset小于(当前读取的最大offset-_spoutConfig.maxOffsetBehind),那么就不把它加到failed集合里,使得它不会被重新处理。如果不落后太多,就把它加到failed集合(所以在消息的一致性要求不高的时候,可以通过maxOffsetBehind来减少fail消息对集群的影响)。
如果还没有消息被ack,并且失败数量太多(numberFailed > _spoutConfig.maxOffsetBehind),就会抛异常,表示PartitionManager工作出错。而这种情况只有在处理第一批消息并且这批消息个数大于maxOffsetBehind才行。
如果前面的条件都没有满足,流程走到了最后一个if-lse(也是大部分消息的处理流程会走到的部分),首先会通过_failedMsgRetryManager.retryFurther(offset)判断这条消息是否还需要重试,如果是,把它加到failed队列,否则将其从failed(如果存在)队列删除,也就是不再处理这条消息。我们来看retryFurther的实现:1
2
3
4
5
6public boolean retryFurther(Long offset) {
MessageRetryRecord record = this.records.get(offset);
return ! (record != null &&
this.retryLimit > 0 &&
this.retryLimit <= record.retryNum);
}
可以看到,判断逻辑为:
- 如果消息还没有重试过(不在failed集合),那么返回true
- 如果消息存在,那么需要retryLimit<0 || retrylimit> record.retryNum
也就是说,可以通过retryLimit(默认为-1)来控制消息的重试次数,所以也可以通过这个参数来避免failed的消息死循环消费问题。